
Our experiment with two databases to control SQI
Currently, our team at Evalueserve is running an exciting experiment using the top databases in the industry to control the recall and precision of our searches.
Many people use multiple databases for their searches. Urs suggests this in his whitepaper. Our team at Evalueserve has always had access to multiple databases. There are tools like Bizint¹ whose key selling point is to combine data from multiple databases. People have been using multiple databases to increase the recall of their searches in general, including in their patent searches. People who have access to multiple databases usually end up comparing the quality of those databases²³. However, people do not use them systematically to control the recall and precision of their search queries. This is the focus of Evalueserve’s experiment.
In this experiment, we are following the steps outlined in Figure 1 below.
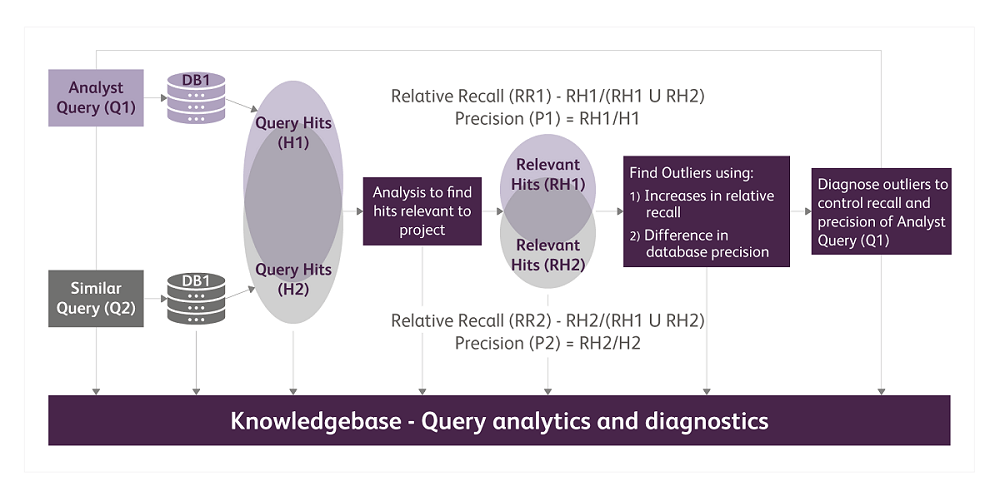
Figure 1: Process flow
We use similar search queries on multiple patent databases to increase the recall of our searches, measure relative recall increase and difference in precision, find outliers, understand why additional recall is being achieved by using different databases and use the learnings as a feedback loop to improve our queries for the current project and future projects. The input and output of each step in the process are systematically analyzed and stored in a central repository (Knowledgebase). We identify outliers for detailed diagnostics using the following two measurements:
- Increase in relative recall because of second database: (1 relative recallDatabase1)/relative recallDatabase1
- Difference in precision of two databases: |P1-P2|/P1
We will use the experiment’s output to improve our understanding of our databases and form queries which are designed specifically to best utilize each database that we subscribe to. This should be done for all recurring alerts, FTO and Intelligence updates that we do currently, and for all projects in future.
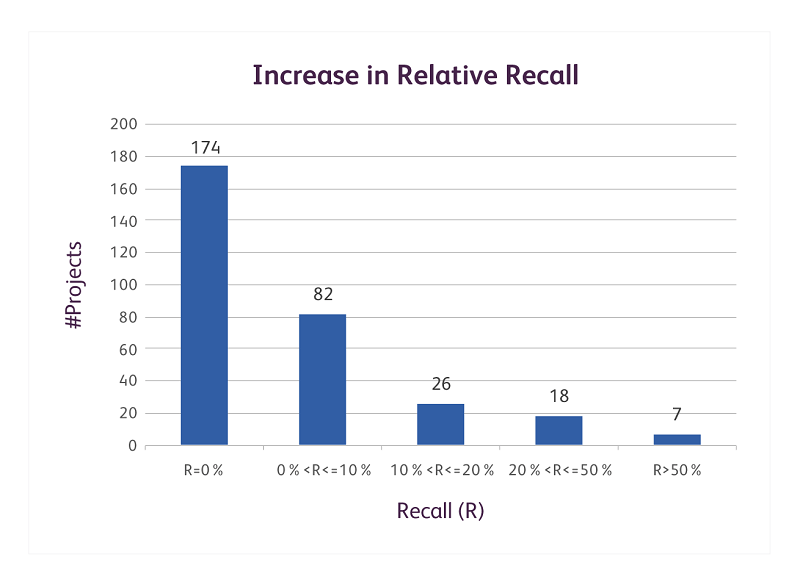
Figure 2: Increase in relative recall using two databases
We have completed the experiment for approximately 300 projects and the initial results are encouraging. Our results recorded in Fig. 2 show that using two different databases had a positive contribution in increasing relative recall for 133 cases. Of these, there was a significant contribution in 51 cases. The cases where relative recall increased by more than 20% call for immediate detailed review of the query. The cases where relative recall increased by less than 10% indicate that at least based on the multiple databases test, the search queries in these projects have a good recall. However, these strings should still be studied to understand the possibilities of increasing precision of the queries without sacrificing on recall.
The theoretical reasons for the difference in results from two databases are being confirmed systematically. We analyzed the reasons for increase in relative recall for 22 out of 25 cases where increase in relative recall is greater than 20%:
- Additional enriched content is the reason behind~30% of the additional results obtained
- Usage of non-equivalent search string because of lack of equivalent searchable fields produced another 24% results.
- Difference in update period of two databases contributed around 24% to the additional results.
- Difference in translation and search algorithms is the reason behind 10.5% and 8% of the additional results obtained respectively.
Additionally, we were able to identify errors made by analysts in more than 10% of the queries. Errors such as incorrect bracket placements, improper field combinations, class format errors, improper usage of double quotes, etc. all become apparent when using two different databases and our automated query converter.
Initial results from the experiment have helped us confirm the following hypotheses around controlling SQI using similar queries on two or more databases:
- The difference between the results of two databases provides immediate value. Using two databases results in additional relevant hits on most projects (immediate recall & SQI increase.) It also provides a strong and immediate signal for query quality. A large number of additional results signal immediate issue. Low numbers of additional results (in combination with expected precision) may signal a correct query but only if additional steps (e.g. secondary queries) indicate no issue. Using two databases also provides the ability to correct wrong query building on live projects.
- Detailed diagnostics helps in identifying and resolving systematic issues. Using two databases helps catch query building errors by analyst such as generic, analyst specific and project specific query issues. It also helps to detect specific database behavior and understand the best ways to capture results from each database. In addition, we gain long-term learnings to build best practices on query building for different databases and train our team on them.
This diagnosis constantly feeds into our best practices for building better queries. The detailed insights we gain into different databases and alternative ways to build better queries provides us systematic ways to control the recall and precision of the search queries to be closer to the expected values.
In the future, we can tweak our experiment in various ways to achieve even deeper insights. For example, we could add more databases to the mix. We could switch between the primary and secondary database. Or, instead of using similar queries, we could use queries that provide close to expected recall based on the behavior of each database. We can always run similar queries corresponding to database specific queries on other databases.
We will share our findings about controlling SQI for our searches in future posts. Follow our blog to see the results of our experiment using multiple databases for our searches and our key learnings about query building.
Refences:
- http://www.bizint.com/pdfs/Combine_Update.pdf
- https://onlinelibrary.wiley.com/doi/abs/10.1002/asi.20498
- https://www.sciencedirect.com/science/article/abs/pii/S0172219017300558


